
tg-me.com/nlp_stuff/362
Last Update:
چه قدر تا بیکارشدن بکاندیها فاصله داریم؟
عمده استفاده برنامهنویسها از LLMها در سطح پیادهسازی فانکشنها و یا ادیت تکههای مختلف کد بوده. اما آیا LLMها میتونند یک پروژه رو به صورت انتها به انتها و ماژولار و البته با کیفیت مناسب پروداکشن پیادهسازی کنند؟ یک کار جالبی اومده که سعی کرده برای همین نیازمندی پیادهسازی انتها به انتها پروژههای بکاندی بنچمارک ارائه بده. این بنچمارک که BaxBench نام داره، ۲۸ تا سناریو نیازمندی تعریف کرده و تلاش کرده با ۱۴ تا فریمورک (از شش زبان مختلف) مختلف این نیازمندیهای رو با LLMها پیادهسازی کنه (یعنی سرجمع ۳۹۲ تسک میشه). از اونور هم ۱۱ تای LLM پیشرو فعلی رو روی این تسکها گذاشته و خواسته که کدشون رو تولید کنند. برای ارزیابی اما چه کرده؟ دو جهت ارزیابی رو در پیش گرفته، یک جهت فانکشنال تستهایی که تعریف کرده و روی کدهای خروجی تست میگیره تا ببینه آیا سیستم درست پیادهسازی شده یا نه، و جهت دیگه هم این که از نظر امنیتی و آسیب پذیری، کدهای نوشتهشده رو سنجیده. برای این کار برای هر سناریو، از یک متخصص امنیت خواسته تا اتکهای ممکن رو تعریف کنه و سپس اونها رو سیستمهای خروجی تولیدشده اجرا گرفتند تا ببیند وضعشون چه طوریه. پس در نهایت کد خروجی LLM میتونه سه وضعیت داشته باشه: اصلا درست نباشه، درست باشه ولی آسیبپذیری امنیتی داشته باشه و در نهایت هم درست باشه و هم عاری از آسیبپذیری.
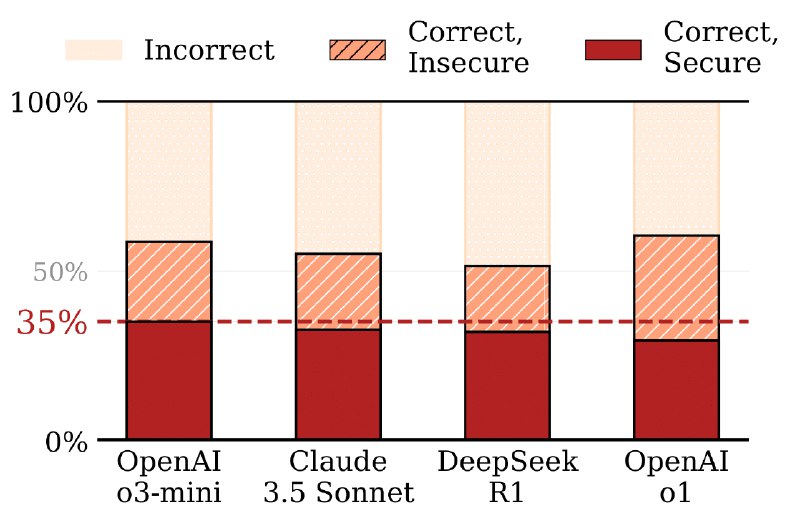
نتایج LLMهای مختلف هم روی این بنچمارک که بهترینشون که o3-mini بوده باشه حدود ۶۰ درصد از تسکها رو تو فانکشنال تست پاس شده که البته نصف همین رقمش هم دچار آسیب پذیری امنیتی بودند و یعنی o3-mini روی این بنچمارک سرجمع فقط ۳۵.۲ درصد تسکها رو براشون خروجی درست و عاری از آسیبپذیری تونسته تولید کنه (البته یک ablation جالبی که زده این بوده که اومده در پرامپتدهی به LLM بهش نکات امنیتی رو گوشزد کرده و همینجوری تونسته درصد کدهای درست امن تولیدشده رو بیشتر کنه) البته o3-mini نه بهترین در تولید کد بوده و نه بهترین در امنیت، بلکه شبیه وزنهبردارها تونسته در مجموع بهترین باشه. در واقع ممکنه یک مدل در تولید کد عملکرد خوبی داشته باشه ولی در امنیت اون کد نه و بالعکس.
اما اکسپریمنتهاش از مقایسه اونوری، یعنی عملکرد روی فریمورکهای مختلف، هم مطابق انتظار این شکلی بوده که LLM ها روی فریمورکهایی که شهرت و محبوبیت کمتری دارند و البته اونایی که برای راهاندازی یک http server نیازمند پیادهسازی در چند فایل هستند عملکرد پایینتری دارند.
در کل، از این پس احتمالا بنچمارکهای انتها به انتهای بیشتری حول و حوش موضوع خودکارسازی توسعه نرمافزار خواهیم دید. روزهای جالبی در انتظاره البته نه برای برنامهنویسها
لینک:
https://baxbench.com/
@nlp_stuff
BY NLP stuff
Share with your friend now:
tg-me.com/nlp_stuff/362